Artificial Intelligence Changing Data Center Horizon
by Will Chang
The Rising Artificial Intelligence Application
AI (Artificial Intelligence) has been a technology people are pursuing for ages. All the movies and novels depicted a fancy imagination about how an AI is helping people improve their lives or maybe control people in a frightening way.
However, for a long time, AI was merely a more efficient way to handle large amounts of data using computers to lookup existing data rapidly. It is not so intelligent, actually, and it takes lots of manual work to help the computers to understand the data.
The launch of ChatGPT surprised the world and people start to realize that computers might really have intelligence. ChatGPT is a chat application based on Generative AI, which can generate new content based on existing data used to train the AI. Other similar applications such as MidJourney for image generation and Jukebox for music creation are also gaining attention.
ChatGPT hit a record 100 million active users in two months. Although the application is still in its infancy and has been providing inaccurate information, people are seeing its potential and believe commercial service is not far away.
Microsoft is accelerating data center build to support ChatGPT, Amazon announced they are developing the same AI technology, and even Elon Musk tried to build another AI project although he was publicly against OpenAI.
Data center is the battle field
The AI war has begun and the battle field is at the data center. ChatGPT now is trained with 300 billion words and has approximately 175 billion parameters to generate context. For GPT-4, the parameters are expected to be in the trillions.
The traffic pattern for AI/ML cluster is very different from general data center applications. The training of AI involves thousands of GPU cards collaborating together to process data sets. The term “collaborate” is very important because one job is considered done when all GPUs finish data processing, before they can move on to the next job.
To optimize training efficiency, the network design is crucial to provide a low latency, zero congestion and high-speed interconnect.
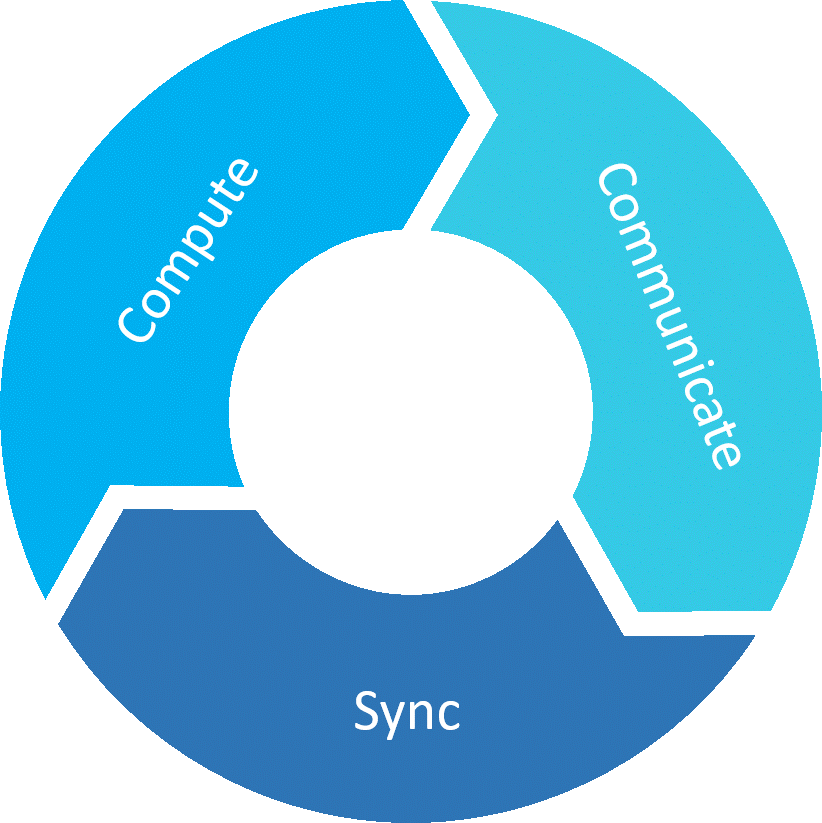
AI Training Involves Repeating of Three Steps
Broadcom Trident 4 Series
The Broadcom Trident 4 series is the latest product of Trident family. The Trident product line is balanced with bandwidth and functionalities. Main features include but are not limited to dynamic load balancing, resilient hashing and programmable pipeline, which are suitable to build a fabric network for AI/ML clusters.
The Trident 4 (TD4) has many variants available from 2.0Tbps to 12.8Tbps switching capacity. All are crafted with 7nm process providing a high performance and low power consumption ASIC. We have briefly introduced some notable features of TD4 with S9300-32D in our previous blog, The 400G Network Transformation of Data Centers. Let’s explore some more features brought by TD4 that’s being adopted by UfiSpace's data center portfolio and see how could we build up a high efficiency and high performance data center network.
Congestion free and feature rich design
UfiSpace offers two products based on the TD4 platform. The first is the S9300-32D, which is equipped with the TD4-X11 and 12.8Tbps switch capacity with 32x400G interfaces. It can be positioned at the spine layer of data center fabrics offering high speed packet exchange. The second is the S9301-32DB, which uses the TD4-X9, an 8.0 Tbps switching ASIC. With its 160x50G PAM4 SerDes, the S9301-32DB is configured to provide 24x200G+8x400G interfaces.
Besides the high bandwidth they can offer, TD4 supports multiple load-balance and congestion management features to optimize the traffic efficiency. We had talked about Dynamic Load Balancing and In-band Telemetry in previous blog article. The support of Dynamic Load Balancing (DLB) allows the traffic load to be redistributed and avoid a congestion. To optimize network configuration, In-band Telemetry can provide a mechanism monitoring traffic status and help to analyze the traffic pattern to optimize network efficiency.
TD4 has two more interesting features to improve network efficiency and flexibility: Explicit Congestion Notification (ECN) and Programmable Pipeline.
Explicit Congestion Notification
Explicit Congestion Notification (ECN) marking is a mechanism to send out notification of network congestion. Traditionally, when there is a congestion, switches will drop packets and the dropped packets would notify sender about the congestion so that the sender could reduce the transmission rate to relieve the congestion. With ECN, the intermediate ECN-aware switch will put a mark in IP header instead of dropping a packet. Afterwards, it will send the packed with the header to the receiver node so that the receiver node could negotiate with the sender node to reduce the transmission rate to prevent data drop. This way, it can reduce the packet drop rate and avoid delays caused by retransmission.
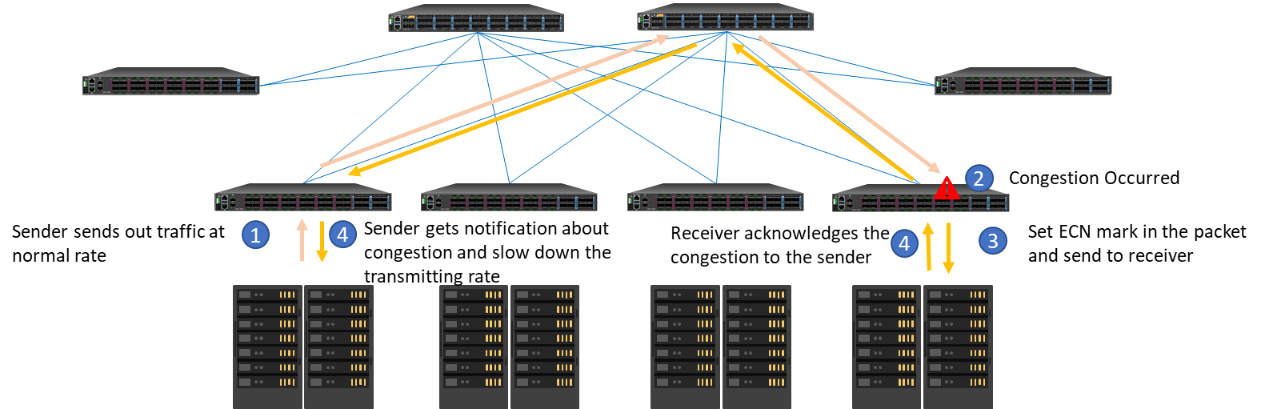
ECN Working Flow
Programmable Pipeline
Broadcom had introduced programmability on Trident 3, but it requires Broadcom's support to add new features. Trident 4 is designed with a tile-based architecture and can be flexibly programmed through a high level Network Programming Language (NPL) and offers enhanced in-field functionalities for users.
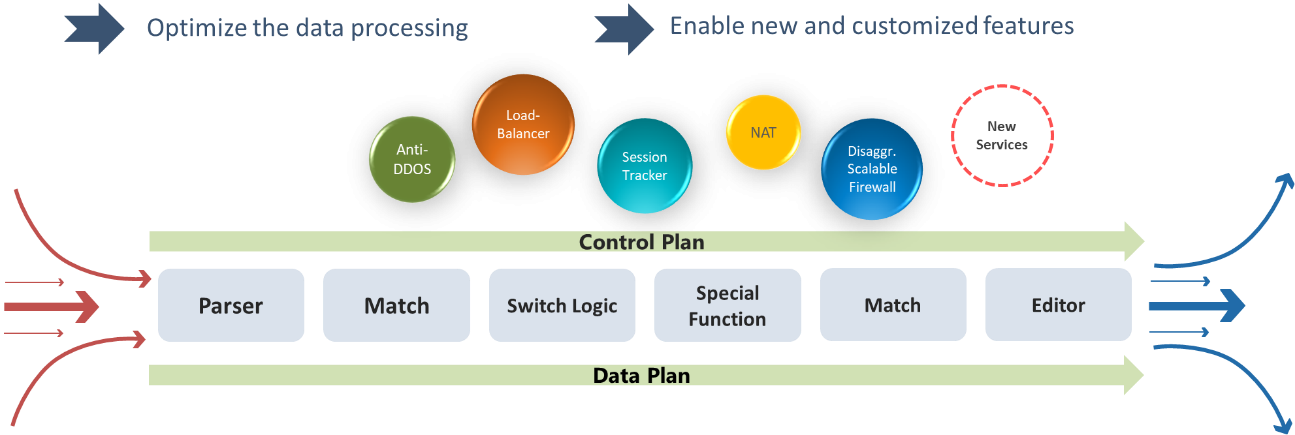
Programmable Pipeline
The chip architecture is composed with 3 major components:
• Flexible components are main functional blocks of programmable pipeline, they are in charge of the packet parsing, modification and data lookup.
• Special functions are handling tasks can’t be done through NPL and providing complex manipulation on packet through SDK.
• Flexible control structures coordinate the activities of flexible components and serve as interfaces to and from special functions.
With programmable pipeline, end users could add new and custom features that optimize packet processing efficiency and gain further control over the power and latency in their network.
UfiSpace 400G data center solutions
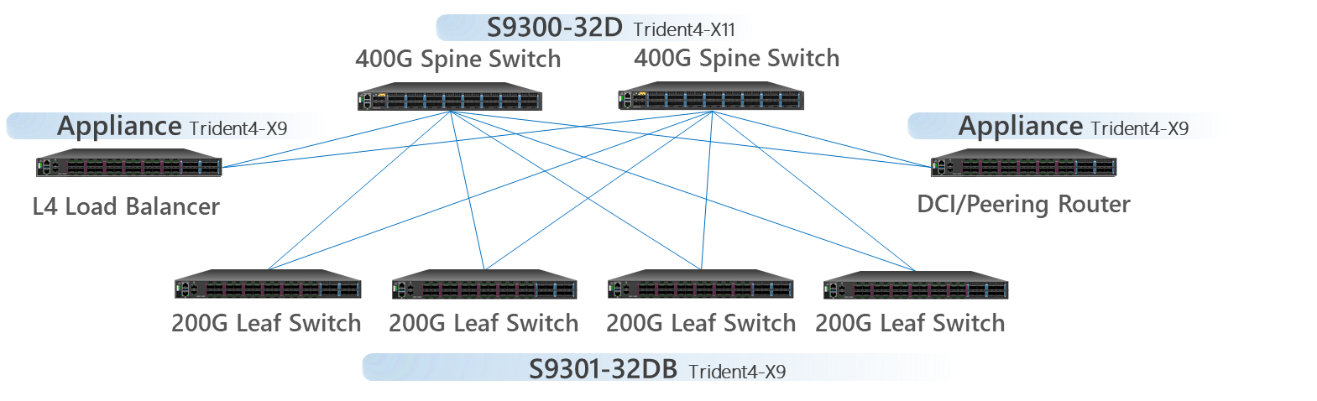
UfiSpace Data Center Solutions
S9300-32D and S9301-32DB can form a highly efficient spine-and-leaf fabric to interconnect GPUs and storage and increase performance. 200G interfaces offered by S9301-32DB can be configured to 2x100G or 1x200G to provide more flexibility when connecting to servers. This enables high speed communication and 400G uplinks between spine and leaf to enable a non-blocking interconnect.
The high performance and programmable design make TD4 also a perfect solution to be used as network appliance such as L4 Load Balancer, Large Scale NAT or DCI/Peering router. The complete offering of Trident 4 platforms provides a hassle-free approach to building up a high speed, flexible and efficient data center fabric.
UfiSpace’s S9300-32D (TD4-X11) and S9301-32DB (TD4-X9) are available for testing now. If you would like to get more details of our data center products, please contact our sales team.