High efficiency and utilization networking through DDC Architecture
by Will Chang

Modern AI technologies have been developed for decades. Two factors have contributed to the recent leap of Generative AI: huge amounts of data and parallel computing. We covered the scale challenges of AI networks in our previous blog. Now we will dive into network efficiency and discuss how the UfiSpace Distributed Disaggregated Chassis (DDC) solution can help optimize network utilization and reduce job completion time.
Traffic patterns of AI training
The traffic pattern of AI networking is very different from a traditional data center scenario. It involves iterations of data exchange, processing, and regression.
There are different algorithms and models for AI training, but the concept is the same: huge amounts of data are spread to GPUs for processing, and the result is synced up to finalize computation. One round of the computation job is complete when all nodes finish their job and the result is synced. The process then repeats until all the training is finished.
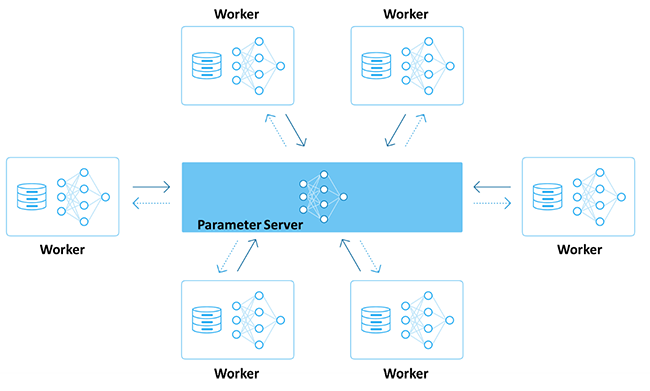
Figure 1 Parallel computing topology for AI training
Based on the process, we can identify some patterns of AI training networking:
1. Fewer flows with higher bandwidth
Unlike traditional data center services which deliver all kinds of traffic, AI networking delivers high bandwidth and a predictable amount of data.
2. Burst traffic
Data is exchanged when the job is dispatched and syncs back results at the same time.
3.Synchronized process
The GPUs need to synchronize with each other to finish a job.
Network challenges
It is fair to say that AI training performance depends on the efficiency and utilization of the network. It is a highly synchronized and collective operation involving multiple peer-to-peer data exchanges. The operation is complete when each node has finished its job, and inconsistent delays will impact the overall performance.
The data exchange is so huge that particular paths will become congested if the routes are not configured properly, and the consequences of a link failure may be significant.
We therefore require a network that provides:
● Low and consistent latency
● High utilization
● High stability
DDC architecture provides high efficiency and utilization networking
Low and consistent latency
The CLOS architecture used to build DDC interconnections guarantees that all packets have the same hops from the source to any destination node. In a two-layer DDC, data travels through the source line card switch and the fabric switch to the destination line card switch and takes three hops for the data to transmit.
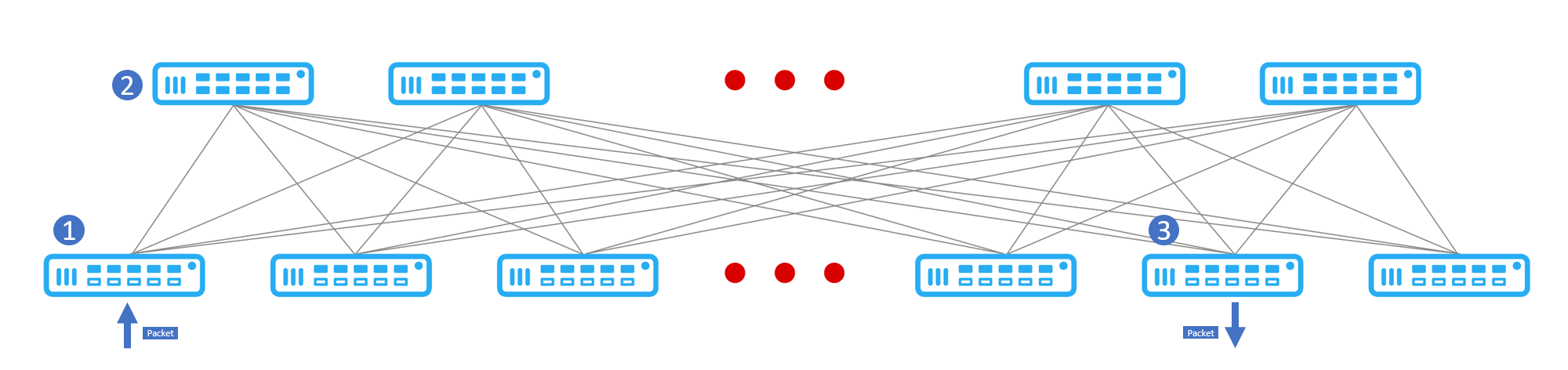
Figure 2 Every node is 3 hops away
A credit-based flow control mechanism is implemented on the Broadcom DNX platform to avoid network congestion. Transmission data is kept in the Virtual Output Queue (VOQ) of the source switch and will not be dispatched to the network until the destination switch gives a green light. This approach ensures the network remains congestion-free and avoids data drops and retransmissions.
Utilization
The interconnections between the line card switch and the fabric card switch use cell-based transmission. Ethernet communication relies on software configuration to optimize the route selection and realize load balancing. The DDC cell-based switching supports load balancing by breaking ethernet packets into smaller, fixed-length cells and then distributing them through available fabric interfaces. Since cell-based switching equally disperses data cells over all fabric links, the link utilization remains equal regardless of the size of the data flow. This avoids the imbalance caused by the route selection algorithm.
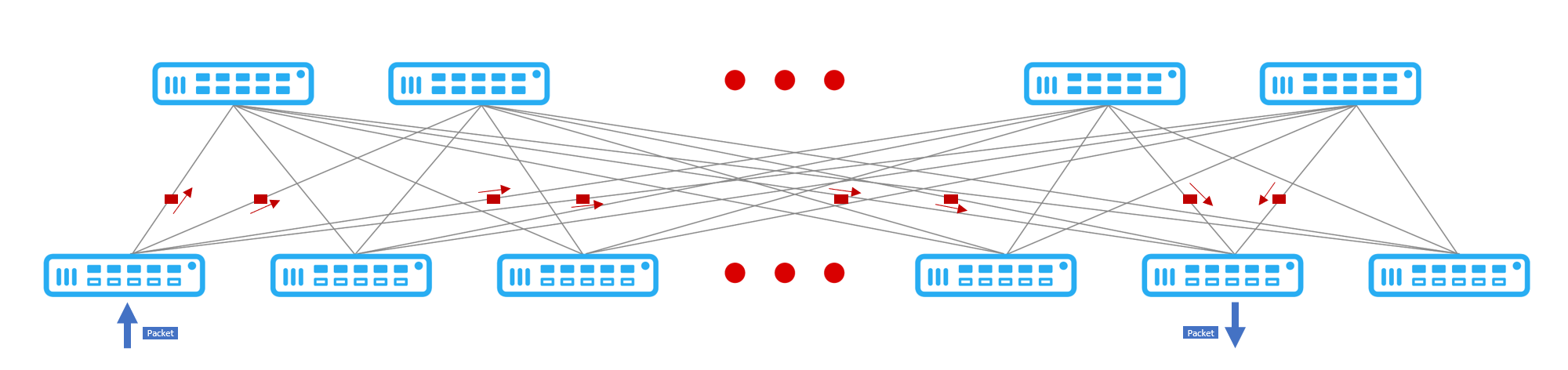
Figure 3 Cell Switching Optimizes the Link Utilization
Failover
The DDC architecture ensures a stable interconnect by creating a mesh network that enables data to reach any destination through any route. Link failures can be detected at a hardware level instead of relying on a software-based detection mechanism. The central controller then calculates and updates the forwarding table to redirect traffic. These processes are completed in nano-seconds and minimize the impact of link failure.
Take away
AI training is a collective and synchronized operation that involves tens of thousands of computing nodes. The bottleneck shifts from computing components to communicating components. To optimize the utilization of GPUs, we must first improve the network utilization and efficiency. UfiSpace’s DDC solution provides a low latency, load-balanced, and highly utilized network interconnect that fulfills the demands of AI applications.
For more information, please contact our sales team.
About the Author
 |
Will Chang Will Chang, Technical Marketing Manager at UfiSpace, provides technical expertise and executes marketing campaigns on technical topics. |